有关内存对齐
面试总会问到内存对齐的问题,但是一直没有搞清楚对齐的规则,专门整理一下。(整理的时候也发现,不停的深挖会有越来越多不了解的知识,这啥时候才是个头)
1. 内存对齐的概念
内存对齐就是将元素按一定规则进行对齐,使得访问的速度更高,相当于一种空间换时间的方法。通常是在结构图、类对象这种地方会发生内存对齐。
为什么要内存对齐?主要因为CPU从内存中读取数据的时候,是按照字(word)来读取的(就是能被字整除的地址),一个字是4或者8个字节(32位系统是4字节,64位系统是8字节)。如果没有内存对齐,那么一个数据可能由本来只要读取一次就能读取完变成了要读取两次,所以内存对齐可以提高效率。
2. 在VS上查看内存
在VS2022中,在上方工具栏点击调试->窗口->内存可以打开内存的查看窗口(这里有有内存1234几个选项,应该是没有区别的,只是说可以多开不同的窗口)。
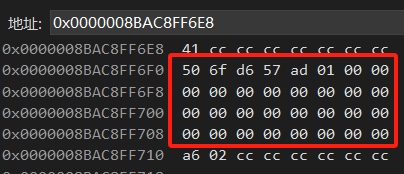
在地址栏直接输入地址或者地址符+变量可以跳转到对应的位置,下方左侧的就是当前对应的地址,右侧是对应的内容,以16进制的方式显示,两个值为一个字节,用空格隔开了。最右侧是可视化,图上给的是ASCII的显示。可以通过右键选择这些显示的方式。
另外看这个内存发现int好像对应不上,搜了一下是因为这个是小端序的关系,才想起来这个多年前学过的东西。大概就是字节的高位和低位的顺序是否与地址的高位低位顺序一直来判断是大端序还是小端序。
小端序:低地址放低位字节,高地址放高位字节。更方便机器处理,因为一般来说按顺序先读取低位计算会更方便。
大端序:低地址放高位字节,高地址放低位字节。更方便人理解。
例如,int类型的10进制数
1234567的二进制为0000 0000 0001 0010 1101 0110 1000 0111,16进制为0012D687,具体的来说两个16进制则为一个字节,所以4个字节分别是00、12、D6、87。地址从左到右是低地址到高地址,如果是大端序的话就是00 12 D6 87,这样高位的字节是在左边的,这种方式和人理解的方式一直,比较直观。如果是小端序则是87 D6 12 00,低位字节也是在低位地址这边,人读的时候需要按字节反转过来才能理解,但是机器先读取低位字节是更方便的。
3. 内存对齐的规则
第一个成员在偏移量为0的地址处。
其他成员变量对齐到对应对齐数的整数倍地址处(数组就按其元素的类型为标准,如果是嵌套则是看嵌套的内部最大对齐多少为标准)。
结构体总大小为内部成员变量最大对齐数的整倍数。
关于对齐数是多少如下所示。
引用wiki上的
一个char(一个字节)变量将被1字节对齐。
一个short(两个字节)变量将是2字节对齐的。
一个int(四个字节)变量将是4字节对齐的。
一个long(四个字节)变量将被4字节对齐。
一个float(四个字节)变量将是4字节对齐的。
一个double(8个字节)变量在Windows上是8字节对齐的,在Linux上是4字节对齐的(用-malign-double编译时选项是8字节)。
一个long long(8个字节)变量将被4字节对齐。
一个long double(C++Builder和DMC为10个字节,Visual C++为8个字节,GCC为12个字节)变量在C++Builder上将是8字节对齐,DMC为2字节对齐,Visual C++为8字节对齐,GCC为4字节对齐。
任何指针(四个字节)都将是4字节对齐的。(例如:
char*,int*)与32位系统相比,LP64 64位系统在对齐方面唯一值得注意的区别是。
一个long(八个字节)变量将是8字节对齐的。
一个double(8个字节)变量将是8字节对齐的。
一个long long(8个字节)变量将是8字节对齐的。
一个long double(在Visual C++中是8个字节,在GCC中是16个字节)变量在Visual C++中是8字节对齐的,在GCC中是16字节对齐的。
任何指针(八个字节)变量都将是8字节对齐的。
简单总结一下就是,基本上自己本身占多少字节,对齐数就是多少,然后对齐到系统读取的字的大小应该就可以了。
但是有例外,比如32位的double、long long、long double,64位的long double。
其中32位的long long本身8字节对齐到4字节还是比较好理解的,因为32位一次也只读取4字节,哪怕8字节对齐了也需要读取两次,和4字节对齐没区别,反而4字节对齐还能节省一些空间。但是double在windows上却是8,long double在不同编译器的时候也不一样,以及64位上GCC编译器时的16字节对齐,这些没太搞懂,问了下GPT大概就是硬件问题、兼容性问题等,还有待研究。
此外这个时候突然想到一个问题,既然像int这样的4个字节的,cpu也能一次读取完,为什么还是需要用小端序存储呢?然后问了下GPT,大致就是小端序并不是为了读取更方便,而是为了处理更方便。
比如:将一个 int 直接转换为 short 或 char,不需要调整指针,只需访问低地址部分的字节;可变长度数据类型的处理时,在内存中可以很容易地将数据从32位扩展到64位,或者将64位数据截断为32位,而大端序则必须调整指针访问高地址;小端序可以确保不同字长的数据在相同地址上具有相同的低位表示,这使得在不同架构上共享或传输数据时更加方便(例如在网络协议或文件格式中)。
4. 实验
4.1. 简单的类型
比如定义如下一个结构体。
typedef struct {
int a;
int* p;
char c;
short s;
double d;
bool b;
}struct1;然后像下面这样初始化然后输出一下对应的内容。
int i = 10;
struct1 s1 = {
1234,
&i,
'c',
123,
123.4,
true
};
cout << "size of struct1 : " << sizeof(s1) << endl;
cout << "offset of a : " << offsetof(struct1, a) << endl;
cout << "offset of p : " << offsetof(struct1, p) << endl;
cout << "offset of c : " << offsetof(struct1, c) << endl;
cout << "offset of s : " << offsetof(struct1, s) << endl;
cout << "offset of d : " << offsetof(struct1, d) << endl;
cout << "offset of b : " << offsetof(struct1, b) << endl;
cout << "done" << endl;可以得到整个街头提的大小以及每一个变量的偏移。
size of struct1 : 40
offset of a : 0
offset of p : 8
offset of c : 16
offset of s : 18
offset of d : 24
offset of b : 32
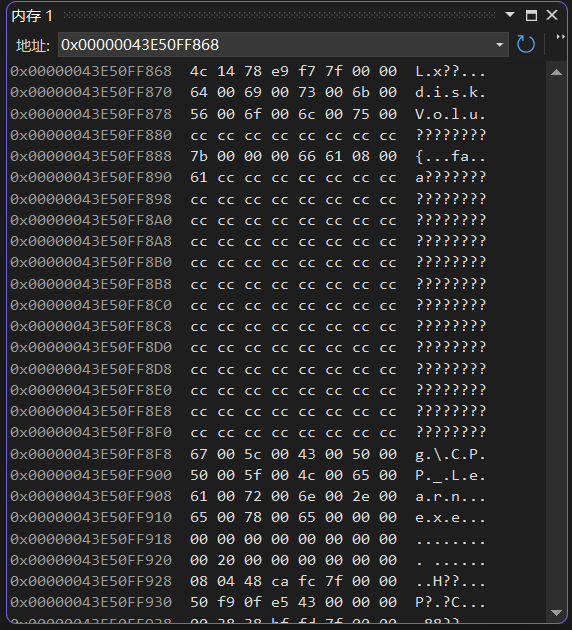
进一步的可以在内存查看的窗口找到对应位置的地址,如下。
画了一下,可以看到第一个红框是整型a,第一个黄框是指针p,蓝框是字符c,绿框是short的s,第二个红框是高精度浮点d,第二个黄框是布尔b,所有的白框就是对齐之后空出来的位置。
4.2. 数组
在结构体中增加一个数组,如下:
typedef struct {
int a;
int* p;
char c;
short s;
double d;
bool b;
short sArr[4];
}struct1;再修改代码执行得到如下输出:
size of struct1 : 48
offset of a : 0
offset of p : 8
offset of c : 16
offset of s : 18
offset of d : 24
offset of b : 32
offset of sArr : 34

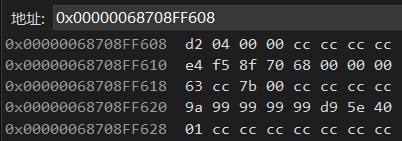
可以看出,数组的short也是按照2字节对齐的,然后后面整个数组就连续的。图中红色的是前面的bool,黄色的长度为4的short数组。同时也发现一个有意思的点,地址0x0000005657CFF660后续的8个字节全都初始化为0了,而观察其他对齐的地方一般默认是0xCC(问了下GPT, 0xCC 是 Visual Studio 的调试模式下的标志字节,未初始化的内存通常会用此填充,方便调试的时候进行观察。release模式下一般不会填充,可能会是随机的)。
然后再做了一些实验,返现上面全部初始化为0应该是因为初始化的问题。之前是使用列表初始化的方式,现在换了下面这种赋值初始化方式:
struct1 s1;
s1.a = 1234;
s1.p = &i;
s1.c = 'c';
s1.s = 123;
s1.d = 123.4;
s1.b = true;
s1.sArr[0] = 0;
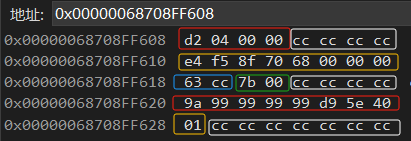
s1.sArr[2] = 0;此时就发现没有初始化的地方就是cc。
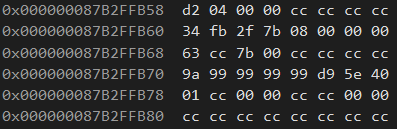
然后才发现,原来结构体内部的成员如果不进行初始化的话,是不会默认初始化的。不过当结构体是一个全局变量的时候是会自动初始化的。
4.3. 嵌套
进一步的,定义一个结构体嵌套起来,此时再查看对齐的结果。
typedef struct {
int a;
int* p;
char c;
short s;
double d;
bool b;
short sArr[4];
}struct1;
typedef struct {
short sh;
struct1 s1;
char c;
}struct2;得到如下的结果,可以看到内部的结构体对齐到了8字节上。
size of struct2 : 64
offset of s1 : 8
offset of c : 56
后续再试了一下,发现这里s1对齐到8是因为内部最大是8,如果s1内部最大是对齐到4字节的话,这个结构体就是对齐到4字节。
4.3. 再加入一个vector对象
尝试在中间加入一个vector。
typedef struct {
char c;
vector<int> vec;
short s;
}struct3;
// 主函数中调用
struct3 s3;
s3.c = 'A';
s3.s = 678;
cout << "size of struct3 : " << sizeof(s3) << endl;
cout << "offset of c : " << offsetof(struct3, c) << endl;
cout << "offset of vec : " << offsetof(struct3, vec) << endl;
cout << "offset of s : " << offsetof(struct3, s) << endl;size of struct3 : 48
offset of c : 0
offset of vec : 8
offset of s : 40
此时发现情况又不一样了,int类型的vector对齐到了8字节而不是4字节,同样这也导致了整个结构体是对齐到8字节的。以及vec本身在中间占了32字节。另外观察内存,可以看到vector的前面存了一些不知道什么东西。稍微研究了一下,是vector这个对象自己的一些东西,包括指向实际放置数据的地址的指针, 因为有指针对齐8字节,那么vector自然也对齐8字节了。(vector自动扩容的时候,是指向所分配的空间扩容,vector这个对象本身并不会发生大小的变化)